This blog post will be updated along with the progress made in the backend student website project. The website can always be viewed here, though in the initial phase it will be a prototype. Once the changes are approved by the mentors, the project will be updated on the original domain. This will be carried out either every week or two weeks, whichever is convenient.
Implementation
Framework to be used
The current backend for BioJS is in node.js. After a discussion with one of the mentors, Rowland Mosbergen, I came to the knowledge that the main sysadmin is more familiar with a python framework. Using a python framework will facilitate more efficient maintenance of the website in the future. Also the sysadmin has ansible for serving a Pyramid/Postgres/Apache server. Hence, time would be saved for the same.
Python frameworks are extremely structured and have better development principles as well as they possess a lot of built-in features. Also they have inherent support for a lot of database systems, including PostgreSQL, which I plan to use for data storage and management. PostgreSQL sorting and querying is a lot faster as compared to MongoDB. Integration with database systems such as MySQL and PostgreSQL is easier when using a python framework.
Final Call
After an intense discussion with Rowland and Dennis, we finally decided to go with Djano. The reasons for the same are as follows:
-
The Django Admin Panel: Probably the greatest strength of the Django framework. This admin panel along with direct staff member and superuser authentication integration would prove extremely useful if creation, reading, updation and deletion(CRUD operations) of any component is required urgently, as logging on to the server and using the shell would not be required. Agreed that an admin panel can be made in pyramid too, but creating such a versatile panel, with many features pre-loaded, would just be an unjust use of time.
-
Django ORM vs SQLAlchemy: SQLAlchemy can be used with both, Pyramid(in the sample scaffold itself) as well as Django(using django-sabridge). An added advantage to Django is the already present and extremely optimized for Django, it’s default ORM. This ORM, again, comes with a number of in-built functionality. The Django ORM works for around 90% of the queries and for extremely complicated queries SQLAlchemy or RAW SQL can be used. In the case of BioJS, this is not an issue as the queries are not very complicated. Also, this means that by using the Django ORM, we are not compromising on the speed. SQLAlchemy is slightly faster as it works closer to the DBMS, but when it comes to simple queries, there is hardly any noticeable difference.
-
Documentation and the learning curve: As pointed by Rowland’s student, Django definitely observes a more structured and extensive documentation as compared to Pyramid. Also, the learning curve of Pyramid is steeper as compared to Django, so for someone new to backend development, and willing to contribute to the project, having it in Django might prove advantageous.
-
Command Line and Task Schedulers: Django has another amazing feature of a common command line interface for all it’s tasks, as compared to Pyramid. Also, the ability to create custom management commands(which basically are functions in Django that can be executed simply by ‘$ python manage.py
’) has an added advantage for Django, where cron jobs can be created easily. As a major requirement for the project is updation of data using the Github API at regular intervals, this would facilitate extremely flexible code, and can be modified/updated whenever required in the future, without changing the cron script. -
Is this worth compromising Pyramid’s biggest strength-Flexibility: Absolutely. Pyramid is widely used on account of it’s flexibility, on account of incorporating multiple databases, using multiple templating languages and extremely easy techniques to change the format of the response render(http, JSON etc). But, the question is : Do we require all this for a website that would solely be working with AJAX calls, without templating and a uniform response instance object? No. So basically, the strength of Pyramid is not a necessity here and hence,
… we chose Django.
Database System
Currently, the development plan for the backend requires MongoDB to be used as the database management system. As discussed with Rowland Mosbergen, I proposed to use PostgreSQL for the project. This is due to:
- Storing the data in a relational table would be more efficient than in JSON format since data retrieval can be made by querying on the columns. The required key, value pairs can easily be parsed for a JSON response.
- The database is perfectly structured. The biggest advantage, or disadvantage of MongoDB is that it has a flexible schema. Keeping scalability in mind, the database is uniform for all the components. The schema would be updated in the future to incorporate new pieces of data.
- Postgres has a strongly typed schema that leaves very little room for errors.
- Database size required would be very less compared to MongoDB since Postgres stores information more efficiently and data isn’t unnecessarily duplicated across tables.
- Below is a comparison of performance between MongoDB(latest stable release : 3.6.3) and PostgreSQL(latest stable release : 10.3)
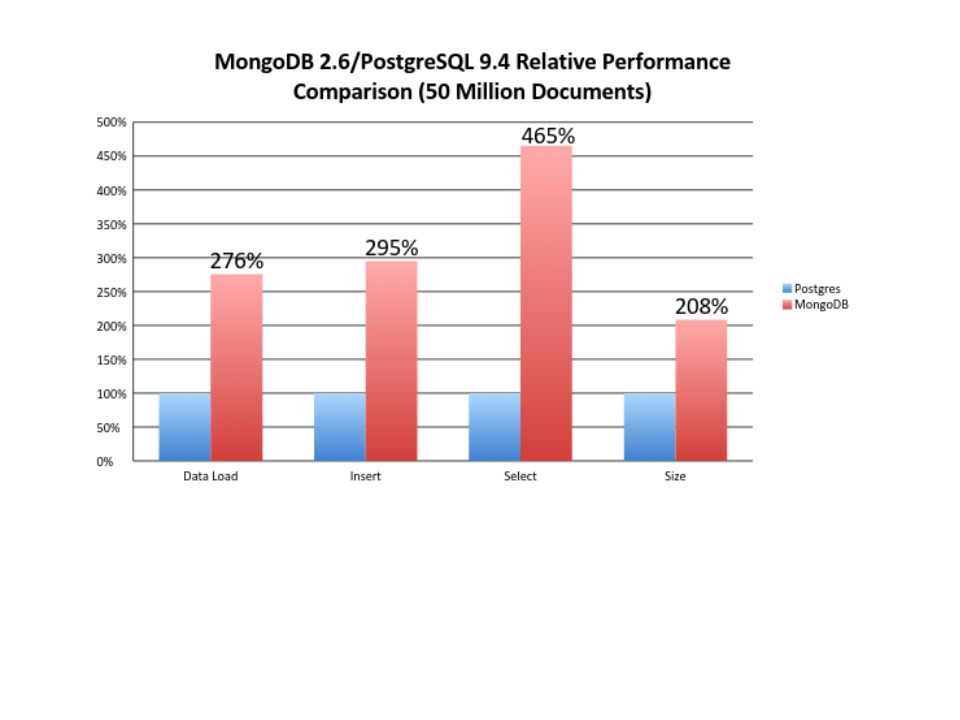
- Also, the sysadmin is more familiar with PostgreSQL. So in a wider scenario, it will prove to be a better option.
Implementation of data transfer using AJAX/Comet
All the requests will be made using AJAX or Comet, with the response in JSON format. It will be easier to be organized in the above mentioned format in a fast and efficient manner.
Serving static files directly using nginx/apache
Whichever reverse proxy is used, the static files(JS, CSS, Images etc.) will be served as normal files from nginx/apache. The path would be specified according to the links created in the front end part. This would mean that the request would need not be forwarded to the application, but would be served directly by the reverse proxy.
Server side caching of Data(If time permits!)
A database such as redis or memcache will be used to cache requests server side. As data would be stored in RAM, it will be served immediately and the functioning of the website will be extremely quick. Another implementation can also be carried out using pyramid-beaker if the pyramid framework is used.
Using cron to keep the database updated
This is probably the most important feature of the project. In order to ensure that the client get up-to-date information of the components, the database will be updated on a timely basis using a cron script. This will be making calls to the Github API as well as to NPM packages. First, it will go through NPM packages, searching for specific tags, such as BioJS and bio-node and create instances of new components everytime it encounters them. After this, it would search Github to update the corresponding information about it’s repository, such as number of forks, stars, contributors etc.
Github only allows 60 unauthenticated requests per hour. To tackle this, the app has been registered on Github. This would enable the server to send 5000 requests to the Github API, using the generated client ID and client secret.
Weekly Progress Report
Tasks completed in Week 1 and Week 2:
-
Creation of the UML diagram based on which the database is structured: The aforementioned UML diagram is shown below. The reason for creation of a separate model for Keywords/Tags is that this would lead to a faster method to find data based on queries. Also, as clearly seen, the Contributors also have a different model. The reason for this is, there is a possibility that the same user is working on more than one component. As a result, advanced queries can also be modelled based on contributors. Further, this would also lead to a major reduction in data redundancy and would further normalize the database.
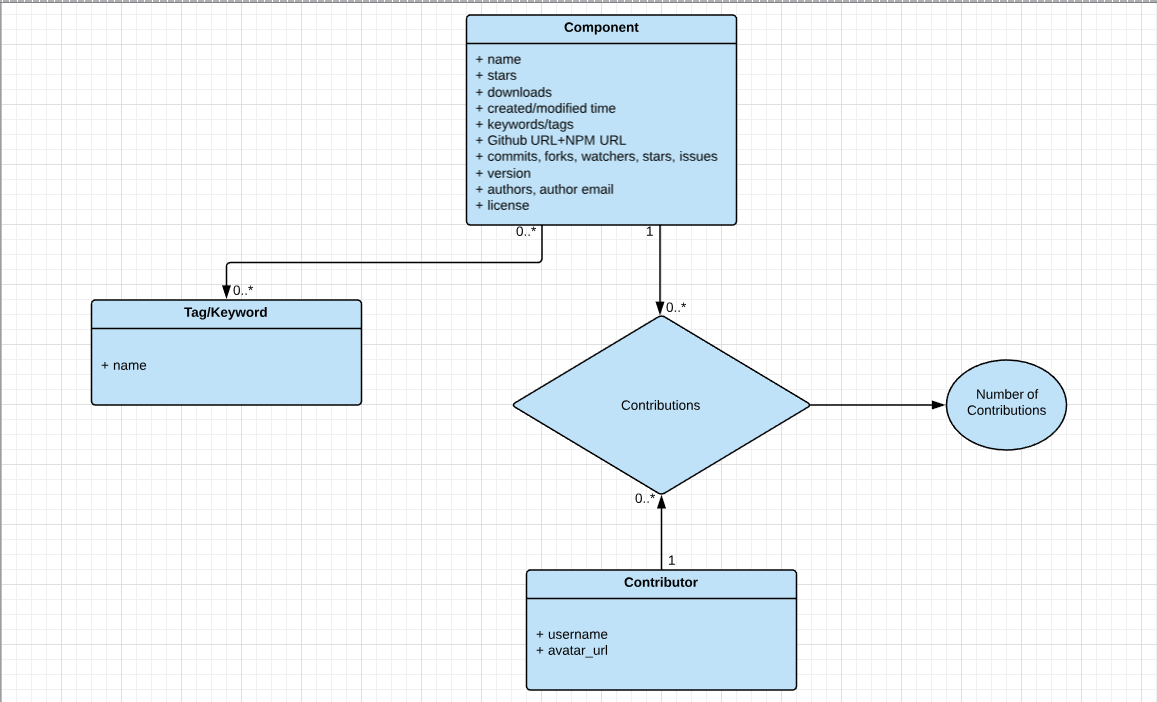
-
Setting up a Django Project connected to a PostgreSQL database: After long discussions, the backend bundle was decided. The project based on the finalised structure has been created. The same is also hosted on a temporary server here.
-
Coding the index API calls with ordering and slicing algorithms for faster rendering of data: As per the UI decided, the landing page demonstrates the Top downloaded components, Top starred components and Most Recent Components. The slicing and projection has been carried out using the built-in filter commands of Django and python list-slicing, with the former known to be extremely efficient. The selected components are later on processed using serializers with support from the Django Rest Framework. The serialiers for the properties are as follows:
from rest_framework import serializers
from .models import *
class DownloadSerializer(serializers.ModelSerializer):
property = serializers.SerializerMethodField()
def get_property(self, component):
return component.downloads
class Meta:
model = Component
fields = ('name', 'property', 'id', 'url_name')
class StarSerializer(serializers.ModelSerializer):
property = serializers.SerializerMethodField()
def get_property(self, component):
return component.stars
class Meta:
model = Component
fields = ('name', 'property', 'id', 'url_name')
class RecentComponentSerializer(serializers.ModelSerializer):
property = serializers.SerializerMethodField()
def get_property(self, component):
return component.modified_time
class Meta:
model = Component
fields = ('name', 'property', 'id', 'url_name')
- Writing the management command for the proposed cron job: As already mentioned, this is the most important feature of the project. One of the strong features of Django is it’s command line interface, especially the ability to call functions using
$ python manage.py <management-command>
This feature has been thoroughly exploited, and will be used for the timely updation of the database, after fetching data from NPM as well as Github, in order to deliver up-to-date information to the client. The code for the management command is as follows:
from django.core.management import BaseCommand
import urllib, json
from main.models import *
from biojs.config import *
def get_github_data(github_url):
response = urllib.urlopen(github_url) # 'https://api.github.com/users/whatever?client_id=xxxx&client_secret=yyyy' format
data = json.loads(response.read())
return data
def get_npm_data():
response = urllib.urlopen("https://api.npms.io/v2/search?q=keywords:biojs")
data = json.loads(response.read())
return data
def get_contributors_data(contributors_url):
response = urllib.urlopen(contributors_url)
data = json.loads(response.read())
return data
class Command(BaseCommand):
# during --help
help = "Command to update the details of all the components from Github"
def handle(self, *args, **options):
all_components = get_npm_data()['results']
for component in all_components:
component_data = component['package']
try:
_component = Component.objects.get(name=component_data['name'])
except:
_component = Component.objects.create(name=component_data['name'])
_component.version = component_data['version']
_component.short_description = component_data['description']
tags = component_data['keywords']
for tag in tags:
try:
_tag = Tag.objects.get(name=tag)
if not _tag in _component.tags:
_component.tags.add(_tag)
except:
_tag = Tag.objects.create(name=tag)
_component.tags.add(_tag)
### Add date after parsing
try:
_component.npm_url = component_data['links']['npm']
except:
pass
try:
_component.homepage_url = component_data['links']['homepage']
except:
pass
try:
github_url = component_data['links']['repository']
url_list = github_url.split('/')
_component.github_url = 'https://api.github.com/repos/' + str(url_list[3]) + '/' + str(url_list[4]) + '?client_id=' + GITHUB_CLIENT_ID + '&client_secret=' + GITHUB_CLIENT_SECRET
except:
pass
try:
_component.author = component_data['author']['name']
except:
pass
try:
_component.author_email = component_data['author']['email']
except:
pass
_component.save()
if _component.github_url:
github_data = get_github_data(_component.github_url)
_component.stars = github_data['stargazers_count']
_component.forks = github_data['forks']
_component.watchers = github_data['watchers']
_component.icon_url = github_data['owner']['avatar_url']
_component.open_issues = github_data['open_issues']
try:
_component.license = github_data['license']['name']
except:
pass
_component.save()
contributors_data = get_contributors_data(github_data['contributors_url'])
commits = 0
count = 0
for contributor in contributors_data:
try:
_contributor = Contributor.objects.get(username=contributor["login"])
except:
_contributor = Contributor.objects.create(username=contributor["login"], avatar_url=contributor["avatar_url"])
try:
_contribution = Contribution.objects.get(component=_component, contributor=_contributor)
_contribution.contributions = contributor["contributions"]
_contribution.save()
except:
_contribution = Contribution.objects.create(component=_component, contributor=_contributor, contributions=contributor["contributions"])
commits += _contribution.contributions
count +=1
_component.commits = commits
_component.no_of_contributors = count
_component.save()
On-going tasks and tasks to be completed during Week 3:
-
Testing and improving the cron job management command: Though the command works well, a time-analysis of the same is a must, which would further help in deciding the time period between subsequent executions of the tab.
-
API Endpoint for component details: Another important task for the third week would be to write the code for delivering the details of the components(as on biojs.io). This needs to be done before the front-end is made as it would lead to faster testing and immediate implementation.
-
Setting up TravisCI for the backend repository: As suggested by Dennis, this is a must and it has to be done by the end of Week 3.